
简介
- 中间件,提供协调服务
- 作用于分布式系统,发挥其优势,可以为大数据服务
- 支持java,提供java和c语言对客户端api
zookeeper=文件系统+监听通知机制
分布式系统
- 很多台计算机组成一个整体,一个整体一致对外并且处理同一请求
- 内部的每台计算机都可以相互通信(rest/rpc)
- 客户端到服务端的一次请求到响应结束会历经多台计算机
自行搜索图解
zookeeper的特性
- 一致性:数据一致性,数据按顺序分批入库
- 原子性:事物要么成功要么失败,不会局部化
- 单一视图:客户端连接集群中任一zk节点,数据都是一致的
- 可靠性:每次对zk的操作状态都会保存在服务端
- 实时性:客户端可以读取到zk服务端的最新数据
安装配置
官网: http://zookeeper.apache.org/
Linux安装
下载: https://archive.apache.org/dist/zookeeper/
解压文件到/usr/local/后配置环境:vim /etc/profile,添加:
1 | export ZOOKEEPER_HOME=/usr/local/zookeeper |
macOS安装
brew install zookeeper //安装位置/usr/local/etc/zookeeper
https://blog.csdn.net/whereismatrix/article/details/50420099
安装启动遇到问题及解决:
zookeeper主要目录结构
zookeeper配置文件介绍
- cp conf/zoo_sample.cfg conf/zoo.cfg
- tickTime
- dataDir必须配置
- dataLogDir建议配置,否则和dataDir公用
- clientPort
zookeeper数据模型
- 是一个树形结构,类似于前端开发中的tree.js组件
- zk的数据模型也可以理解为unix/linux的文件目录
- 每一个节点都成为znode,他可以有自节点,也可以有数据
- 每个节点分为临时节点和永久节点,临时节点在客户端断开后消失
- 每个zk节点都有各自的版本号,可以通过命令行来显示节点信息
- 每当节点数据发生变化,那么该节点的版本号会累加(乐观锁)
- 删除/修改过时的节点,版本号不匹配则会报错
- 每个zk节点存储的数据不宜过大,几k即可
- 节点可以设置权限acl,可以通过权限来限制用户的访问
基本操作:
- 客户端连接:bin/zkCli.sh 可以输入help回车查看支持的命令
- 查看znode结构: ls命令,一层层查看
- 关闭客户端连接: ctrl+c
zookeeper作用体现
- master节点选举,主节点挂了之后,从节点就会接手工作,并且保证这个节点是唯一的,这也是所谓的首脑模式,从而保证我们集群是高可用的
- 统一配置文件管理,即只需部署一台服务器,则可以把相同的配置文件同步更新到其他所有服务器,此操作在云计算中用的特别多(假设修改了redis统一配置)
- 发布与订阅,类似于消息队列MQ(amq,rmq…),dubbo发布者把数据存在znode上,订阅者会读取这个数据
- 提供分布式锁,分布式环境中不通进程之间争夺资源,类似于多线程中的锁
- 集群管理,集群中保证数据的强一致性
四种类型的znode
- PERSISTENT-持久化目录节点:客户端与zookeeper断开连接后,该节点依旧存在
- PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点:客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
- EPHEMERAL-临时目录节点:客户端与zookeeper断开连接后,该节点被删除
- EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点:客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
监听通知机制
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,zookeeper会通知客户端。
Zookeeper客户端的使用
- zkCli.sh:可使用./zkCli.sh -server localhost来连接到Zookeeper服务上
- Java客户端:可创建org.apache.zookeeper.ZooKeeper对象来作为zk的客户端,注意,java api里创建zk客户端是异步的,为防止在客户端还未完成创建就被使用的情况,这里可以使用同步计时器,确保zk对象创建完成再被使用
- C客户端
zookeeper常用命令行操作
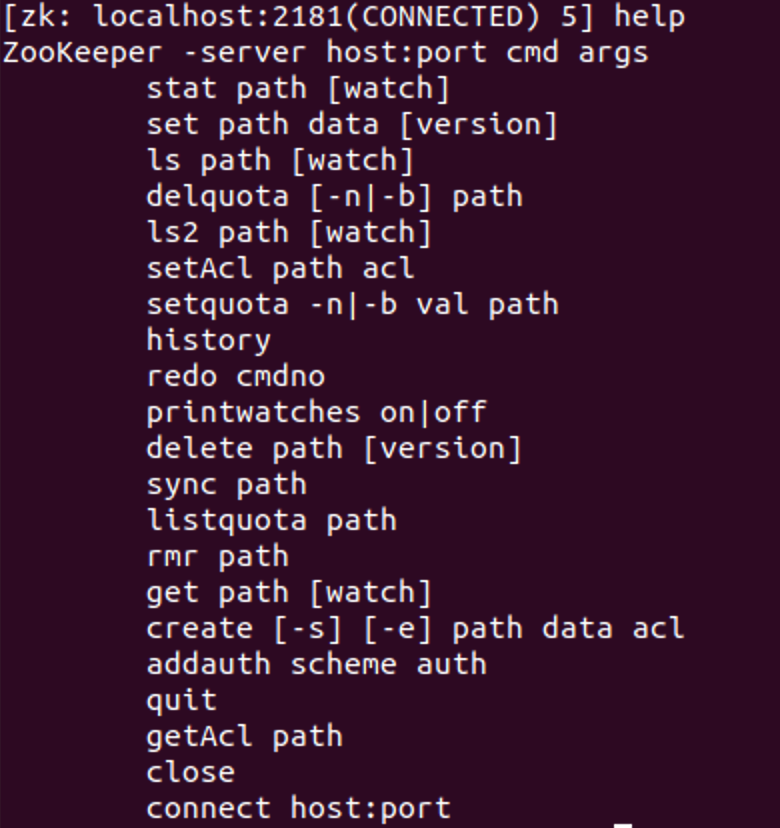
启动服务:./zkServer.sh,连接客户端进入命令行后台:./zkCli.sh
- ls与ls2
- get与stat
zk特性-session的基本原理:客户端与服务端之间的连接存在会话;每个会话都可以设置一个超时时间;心跳结束,session则过期;session过期则临时节点znode会被抛弃
心跳机制:客户端向服务端的ping包请求
zk特性-watcher机制:针对每个节点的操作,都会有一个监督者watcher;当监控的某个znode发生了变化则出发watcher事件;zk中的watcher是一次性的,触发后立即销毁;父节点、子节点增删改都能触发其watcher
事件触发的类型及分类
ACL(access control lists)权限控制
- 针对节点可以设置相关读写等权限,目的为了保障数据安全性
- 权限permissions可以指定不同的权限范围以及角色
登录: addauth digest imooc:imooc
acl命令行
- getAcl:获取某个节点的acl权限信息
- setAcl:设置某个节点的acl权限信息
- addauth:输入认证授权信息,注册时输入明文密码(登录),但在zk的系统里,密码是以加密的形式存在的
zk的acl通过[scheme🆔permissions]来构成权限列表:
- scheme:代表采用的某种权限机制
- world:它下面只有一个id, 叫anyone, world:anyone代表任何人,zookeeper中对所有人有权限的结点就是属于world:anyone的
- auth: 它不需要id, 只要是通过authentication的user都有权限(zookeeper支持通过kerberos来进行authencation, 也支持username/password形式的authentication)
- digest:它对应的id为username:BASE64(SHA1(password)),它需要先通过username:password形式的authentication
- ip:: 它对应的id为客户机的IP地址,设置的时候可以设置一个ip段,比如ip:192.168.1.0/16, 表示匹配前16个bit的IP段
- super:代表超级管理员,拥有所有的权限
1 | //修改zkServer.sh增加super管理员 |
- id:代表允许访问的用户
- permissions:权限组合字符串(crdwa)
- create:创建子节点
- read:获取节点/子节点
- write:设置节点数据
- delete:删除子节点
- admin:设置权限
acl常用使用场景
- 开发/测试环境分离,开发者无权限操作测试库的节点,只能看
- 生产环境上控制指定ip的服务可以访问相关节点,防止混乱
zookeeper四字命令
- zk可以通过他自身提供的简写命令来和服务器进行交互
- 需要使用到nc命令,安装:yum install nc
- echo [command] | nc [ip] [port],如:echo ruok | nc localhost 2181
- stat:查看zk的状态信息,以及是否mode
- ruok:查看当前zkServer是否启动,返回imok
- dump: 列出未经处理的会话和临时节点
- conf:查看服务器配置
- cons:展示连接到服务器的客户端信息
- envi:展示环境变量
- mntr:监控zk健康信息
- wchs:展示watcher信息
白名单设置
zookeeper集群搭建
- zk集群,主从节点,心跳机制(选举模式),服务器数:2n+1
注意事项:
- 配置数据文件 myid 1/2/3 对应server.1/2/3
- 通过./zkCli.sh -server [ip]:[port]检测集群是否配置成功
- 通过./zkServer.sh status查看zk节点在集群中的状态
集群搭建前置
在本地单机配置zk启动及一般操作正常,假设本地zk目录为:/usr/zookeeper
单机伪分布式zk集群搭建
- 准备zk单个节点
1 | sudo mkdir /usr/zookerperGroup |
- 修改相关配置
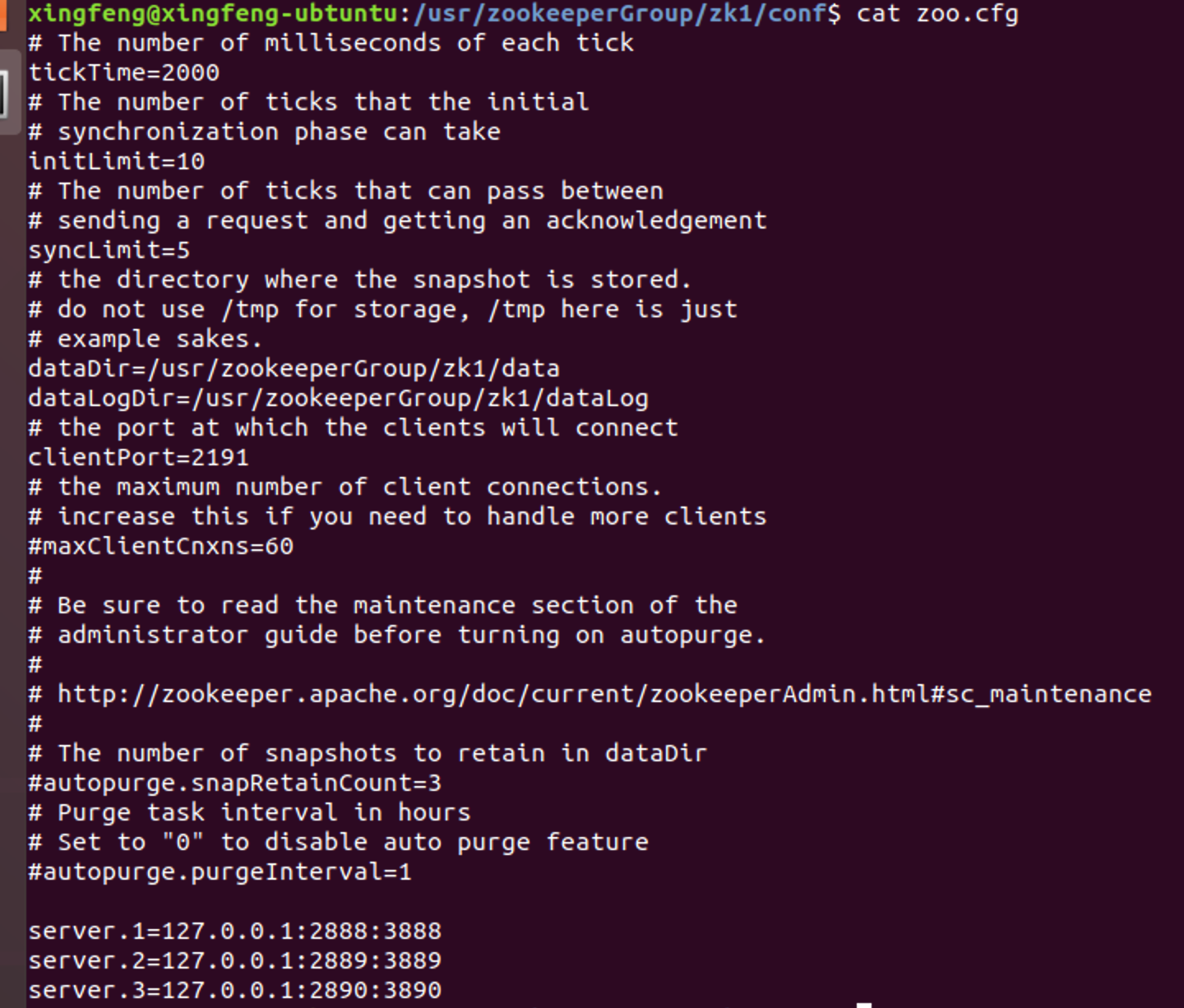
依次进入zk1、zk2、zk3的conf目录,编辑zoo.cfg文件:
- 修改clientPort依次为:2191,2192,2193
- 修改dataDir、dataLogDir路径为:usr/zookerperGroup/zk{X}/data和usr/zookerperGroup/zk{X}/dataLog
- 在文件末添加如下内容:(此处IP地址也可改为实际地址)
1 | server.1=127.0.0.1:2888:3888 |
此配置需细心,切不可漏配、少配,我的配置如下图:
3. 创建myid文件
- 依次进入zk1、zk2、zk3的data目录,sudo vim myid,输入内容依次为:1,2,3保存
- 依次启动zk服务
- 依次进入zk1、zk2、zk3的bin目录,启动zk服务:sudo ./zkServer.sh start
- 测试集群
- 进入zk1的bin,连接zk服务器,如:sudo zkCli.sh -server 127.0.0.1:2191
- 在zk1中创建节点:create /test Hello
- 进入zk2的bin,连接zk服务器,如:sudo zkCli.sh -server 127.0.0.1:2192
- 获取test节点信息,如:ls /;get /test
- 通过sudo ./zkServer status查看集群节点信息
真实环境zk集群搭建
- 需注意:环境变量的配置,ip配置不同,端口号可以相同
- 真实环境就是在多台机器间搭建zk集群,个人的话可通过虚拟机虚拟多台机器的方式学习,此处记录和单机伪分布式部署的不同及简单步骤:
- 在需要搭建集群的节点机器按照本文【安装配置】中方式完成安装和系统环境变量设置;
- 配置各机器网络,保证各机器网络互通,假设有3台机器,其ip地址为:192.168.1.111/112/113
- 修改各台机器的zoo.cfg配置文件
- 配置各机器端口为统一端口,如默认:2181
- 配置dataDir和dataLogDir,尽量各机器保持一致
- 在各机器zoo.cfg文末添加集群配置,如:
1 | server.1=192.168.1.111:2888:3888 |
- 在各机器创建myid文件,sudo vim myid,输入内容依次为:1,2,3保存
- 进入各机器,启动zk服务:sudo ./zkServer.sh start
- 测试集群节点状态:sudo ./zkServer status,通过sudo ./zkCli.sh -server 192.168.1.111:2181,同时通过如上单机伪分布式方式测试数据同步;强制关闭主节点测试主节点选举等
API操作相关代码
ZooKeeper的api支持多种语言,在操作时可以选择使用同步api还是异步api。同步api一般是直接返回结果,异步api一般是通过回调来传送执行结果的,一般方法中有某参数是类AsyncCallback的内部接口,那么该方法应该就是异步调用,回调方法名为processResult。
具体操作代码详见:
缺点:
- 超时重连不支持自动,需手动重连
- watch注册一次后会失效
- 不支持递归创建节点
Apache Curator客户端使用
Curator的Maven依赖如下,一般直接使用curator-recipes就行了,如果需要自己封装一些底层些的功能的话,例如增加连接管理重试机制等,则可以引入curator-framework包。
1 | <!-- https://mvnrepository.com/artifact/org.apache.curator/curator-framework --> |
- curator引入,版本要和zookeeper匹配,具体参考:http://curator.apache.org/zk-compatibility.html
- curator重试连接策略:ExponentialBackoffRetry、RetryNTimes、RetryOneTimes、RetryUntilElapsed
- Curator提供了三种Watcher(Cache)来监听结点的变化:
- Path Cache:监视一个路径下1)孩子结点的创建、2)删除,3)以及结点数据的更新。产生的事件会传递给注册的PathChildrenCacheListener。
- Node Cache:监视一个结点的创建、更新、删除,并将结点的数据缓存在本地。
- Tree Cache:Path Cache和Node Cache的“合体”,监视路径下的创建、更新、删除事件,并缓存路径下所有孩子结点的数据。

