
学习视频:https://coding.imooc.com/learn/list/219.html
简介
人人开源项目:https://www.renren.io/
项目部署图解:
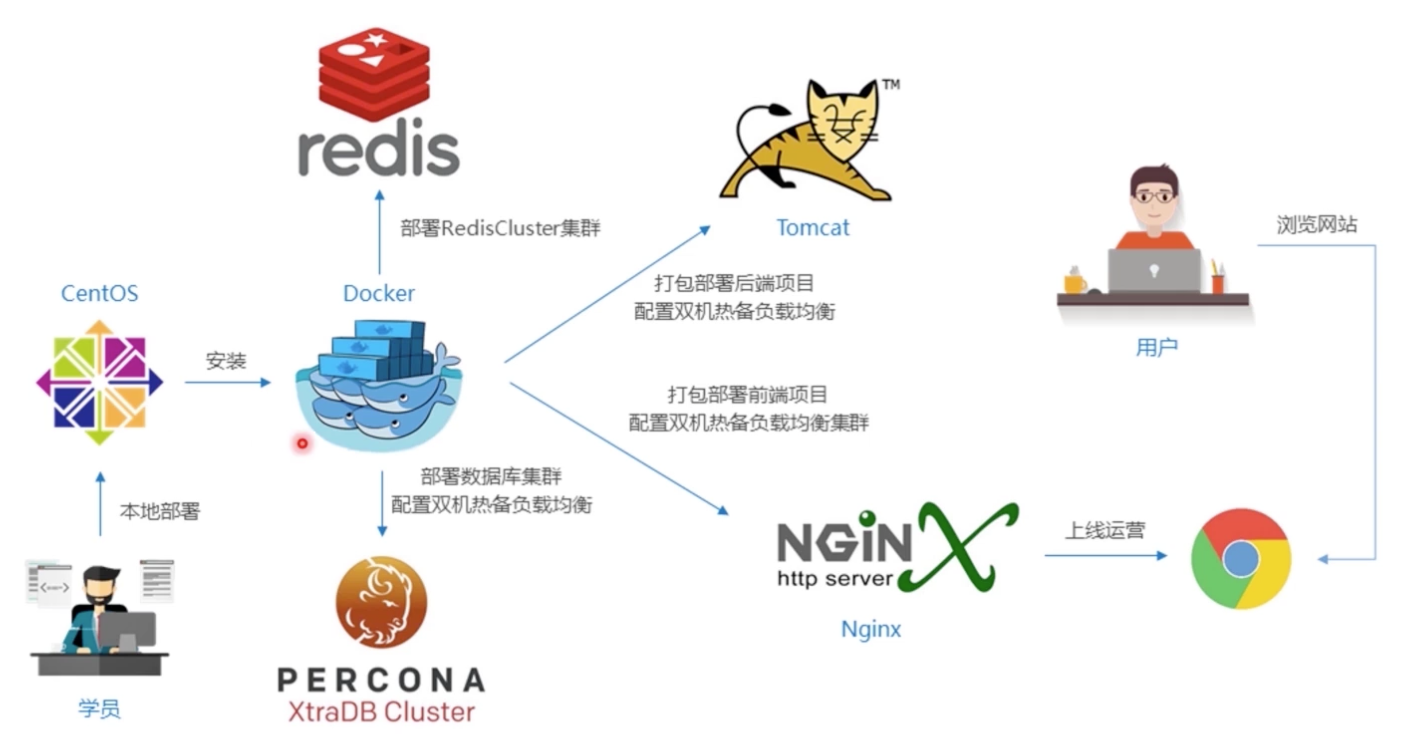
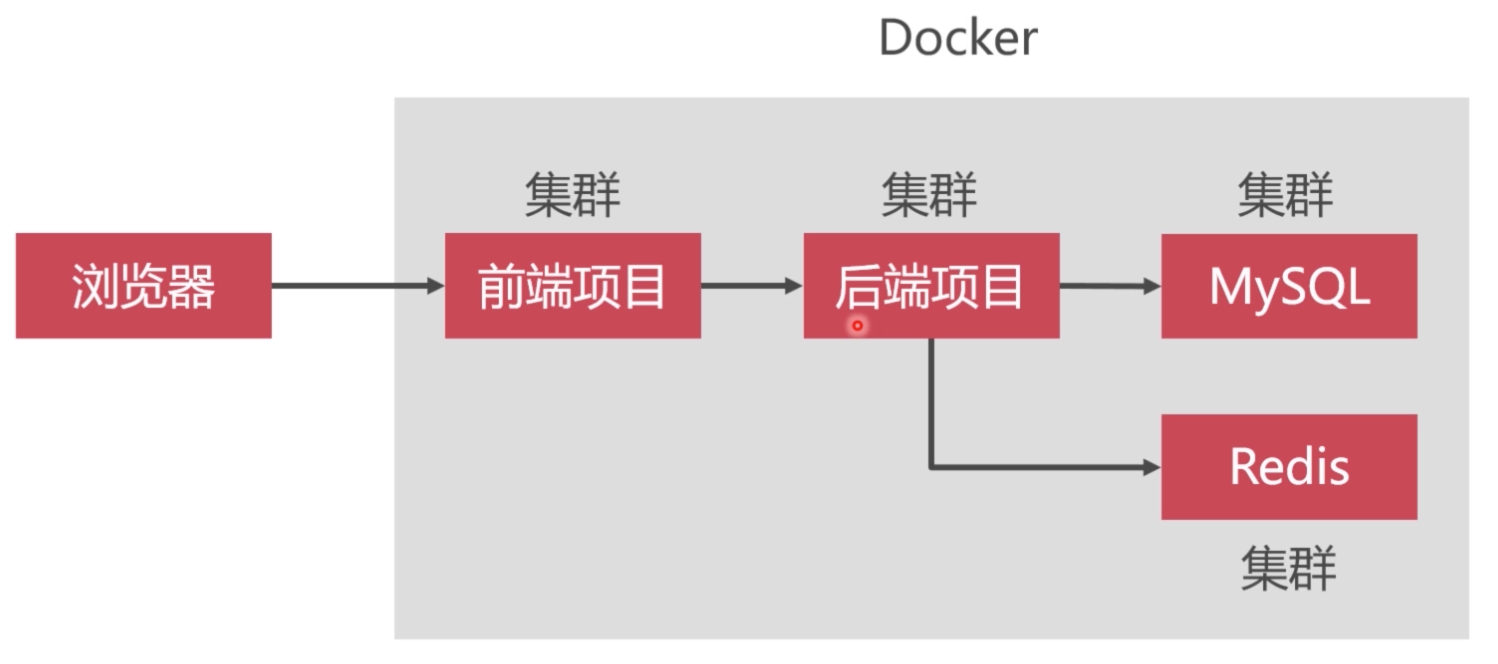
开发环境要求
软件:宿主机-Vmware虚拟机(CentOS/Ubuntu)-Docker虚拟机
MySQL集群
单节点数据库无法满足性能上的要求及高可用冗余设计,大型互联网程序用户群体庞大,架构必须特殊设计,mysql常见集群方案:
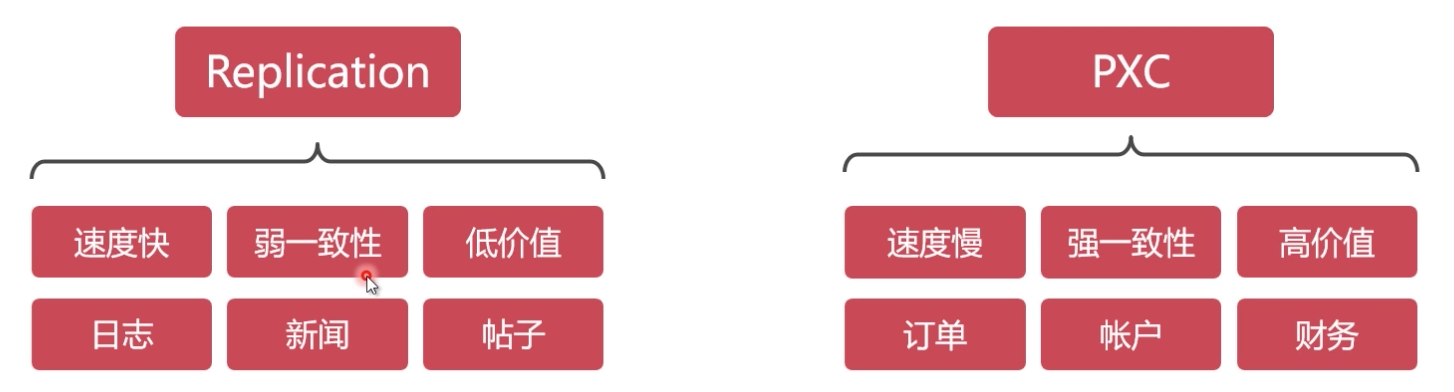
PXC方案原理
PXC(Percona XtraDB Cluster):建议PXC使用PerconaServer(MySQL改进版,性能提升很大)
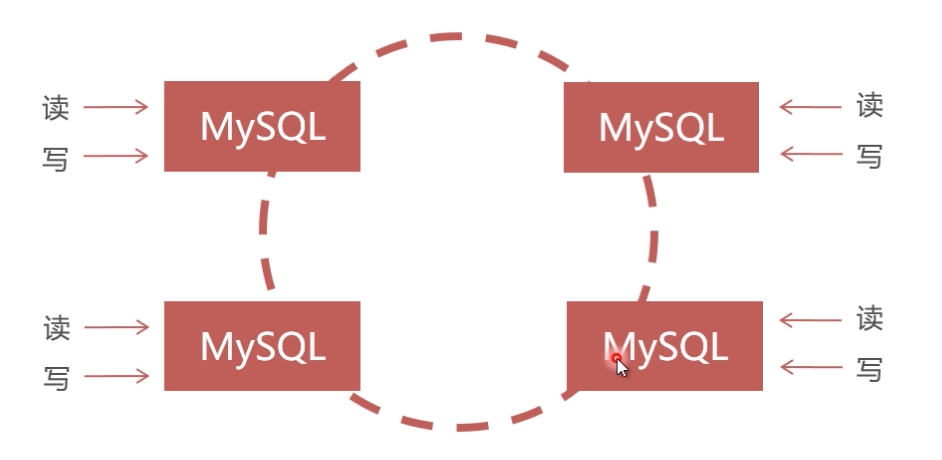
PXC数据强一致性:同步复制,事物在所有集群节点要么同时提交,要么不提交
PXC集群搭建
网络准备:
1 | docker network create --subnet=172.18.0.0/24 net1 |
准备数据卷:
1 | docker volume create --name v1 |
创建pxc容器:每个MySQL容器创建之后,因为要执行PXC的初始化和加入集群等工作,耐心等待1分钟左右再用客户 端连接MySQL。另外,必须第1个MySQL节点启动成功,用MySQL客户端能连接上之后,再去创建其他 MySQL节点。
1 | docker pull percona/percona-xtradb-cluster |
通过客户端测试数据库集群:
- 输入数据库ip为宿主机ip,端口为映射ip,如:3307、3308等连接不同节点
- 任意节点建库、建表测试是否同步
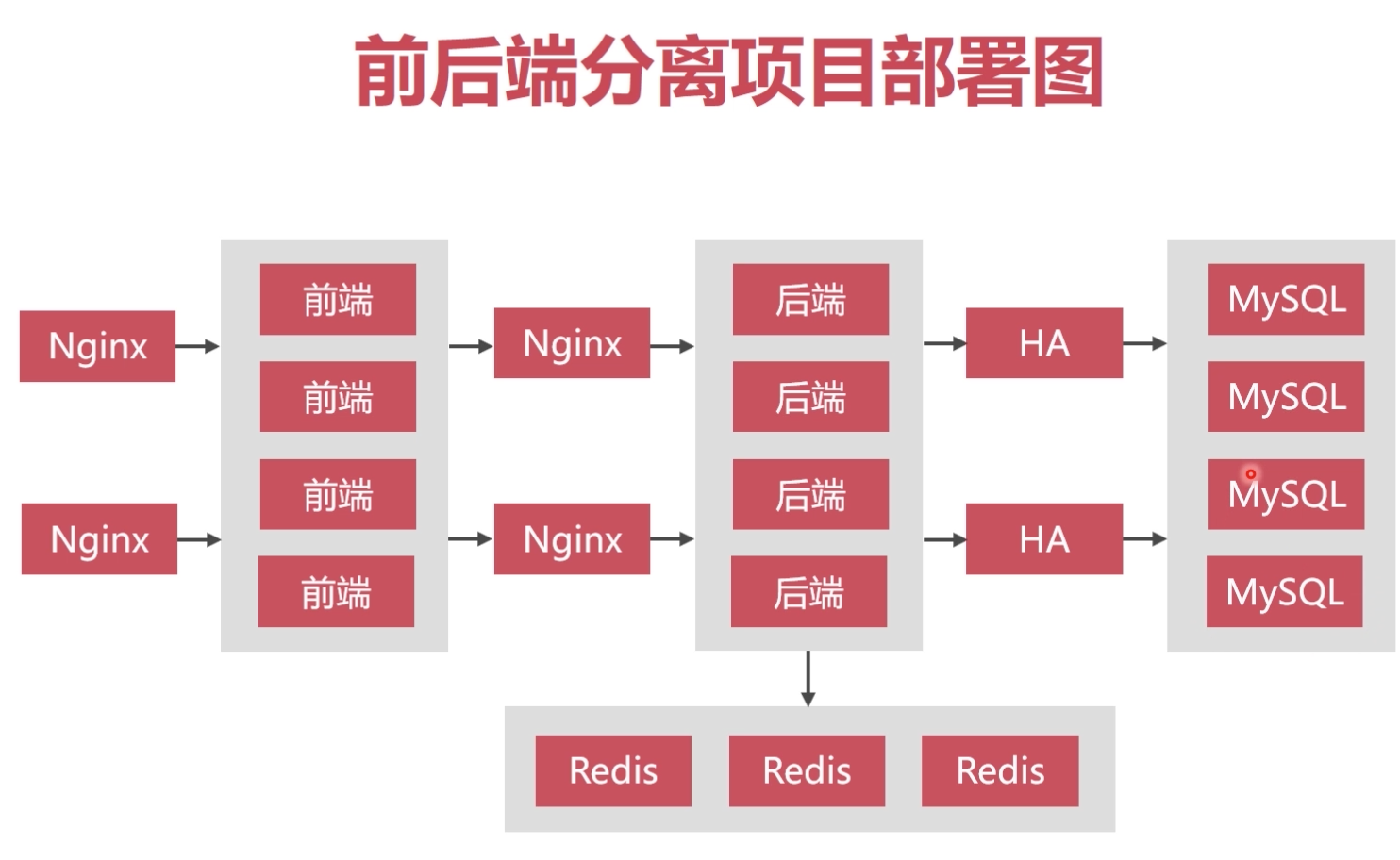
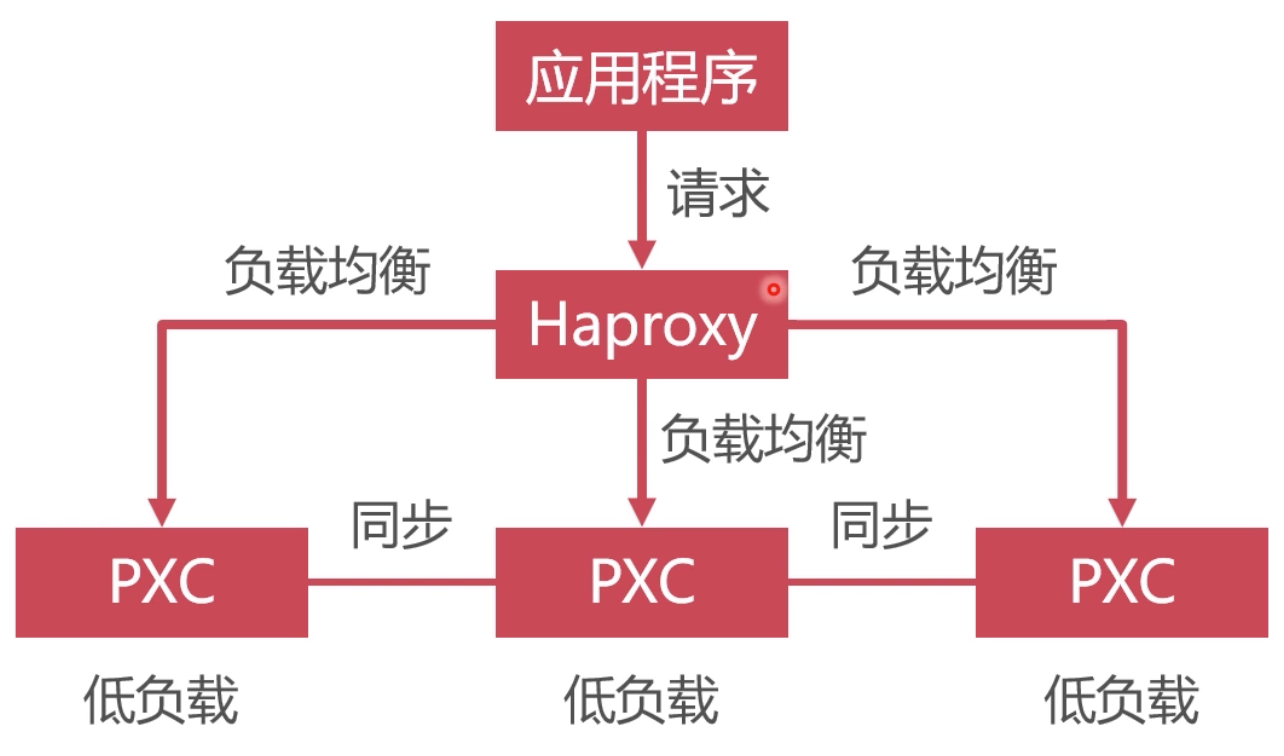
数据库集群的负载均衡
使用Haproxy做负载均衡,请求被均匀分发给每个节点,单节点负载低,性能好
haproxy使用
- docker pull haproxy //获取haproxy系统镜像
- 创建haproxy配置文件: sudo vim /media/psf/LinuxShare/data/conf/haproxy.cfg,更多配置查看:https://zhang.ge/5125.html
1 | global |
- 创建haproxy容器
1 | #创建第1个Haproxy负载均衡服务器 |
- 创建数据库haproxy用户:create user ‘haproxy’@’%’ identified by ‘’;
- 启动haproxy
1 | docker exec -it h1 bash |
- 浏览器访问:
浏览器访问地址:http://宿主机ip:4001/dbs - 数据库访问:
ip为宿主机ip,端口4002,见第三步 - 测试节点宕机
- docker stop node1;查看浏览器,node1节点是否宕机
- 恢复node1节点:删除node1节点,重新以从节点方式创建node1即可
1 | docker rm node1 |
虚拟IP地址技术
keepalived实现双机热备
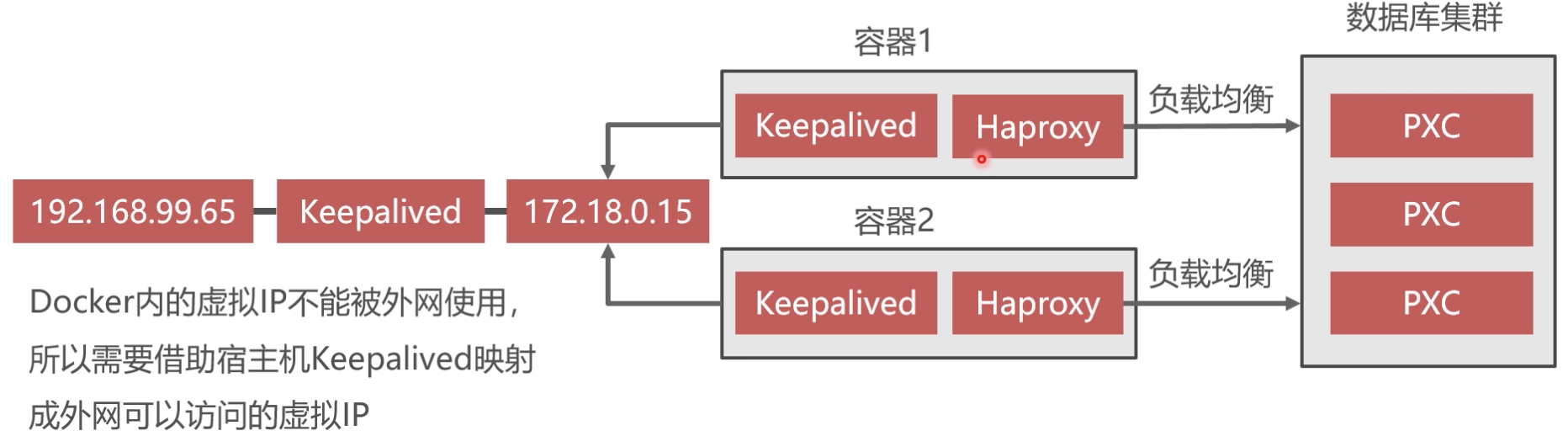
- Keepalived必须安装在haproxy容器内
1 | docker exec -it h1 bash |
配置文件内容为:
1 | vrrp_instance VI_1 { |
1 | virtual_server 192.168.99.150 8888 { |
暂停PXC集群的办法
- 在/etc/sysctl.conf文件末尾添加:net.ipv4.ip_forward=1;重启网络服务:systectl restart network
Replication方案原理
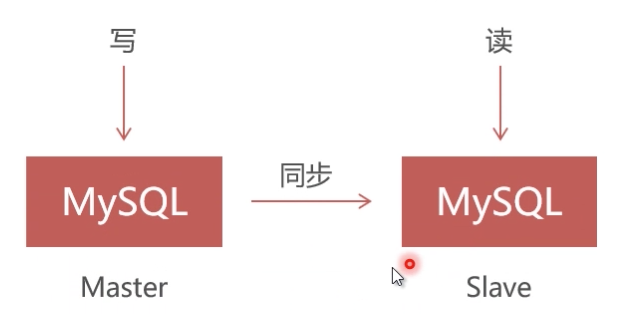
Replication采用异步复制,单向同步,无法保证数据的一致性
参考文章:
–sql
stop slave;
show slave status;
PXC集群安装
MySQL集群(PXC)入门:https://www.imooc.com/learn/993
Redis集群
高速缓存:利用内存保存数据,读写速度远超硬盘;减少I/O操作
Redis集群方案
- RedisCluster:官方推荐,没有中心节点,客户端与redis节点直连,不需要中间代理层;数据可被分片存储;管理方便,后续可自行增删节点
- Codis:中间件产品,存在中心节点,360公司产品
- Twemproxy:中间件产品,存在中心节点
- Redis集群中应该包含奇数个Master,至少应该有3个Master
- Redis集群中每个Master都应该有Slave
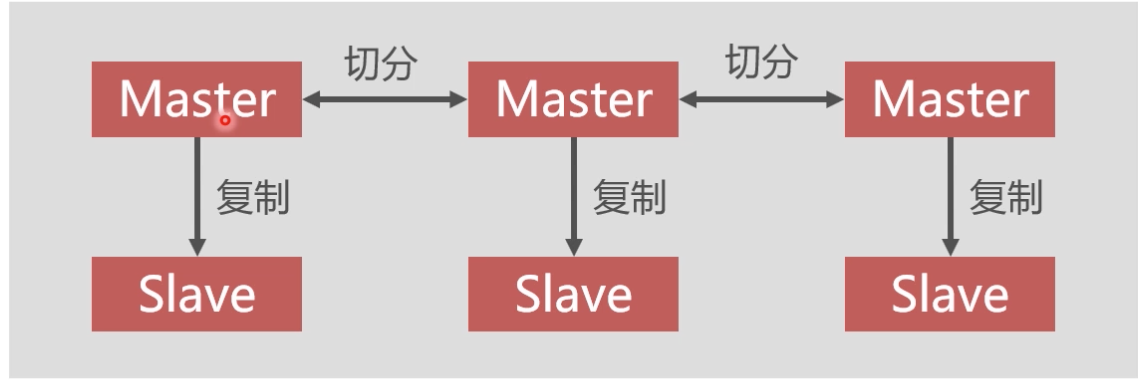
- redis集群不配置负载均衡是因为在前后端分离项目中Spring程序实现了负载均衡
RedisCluster架构
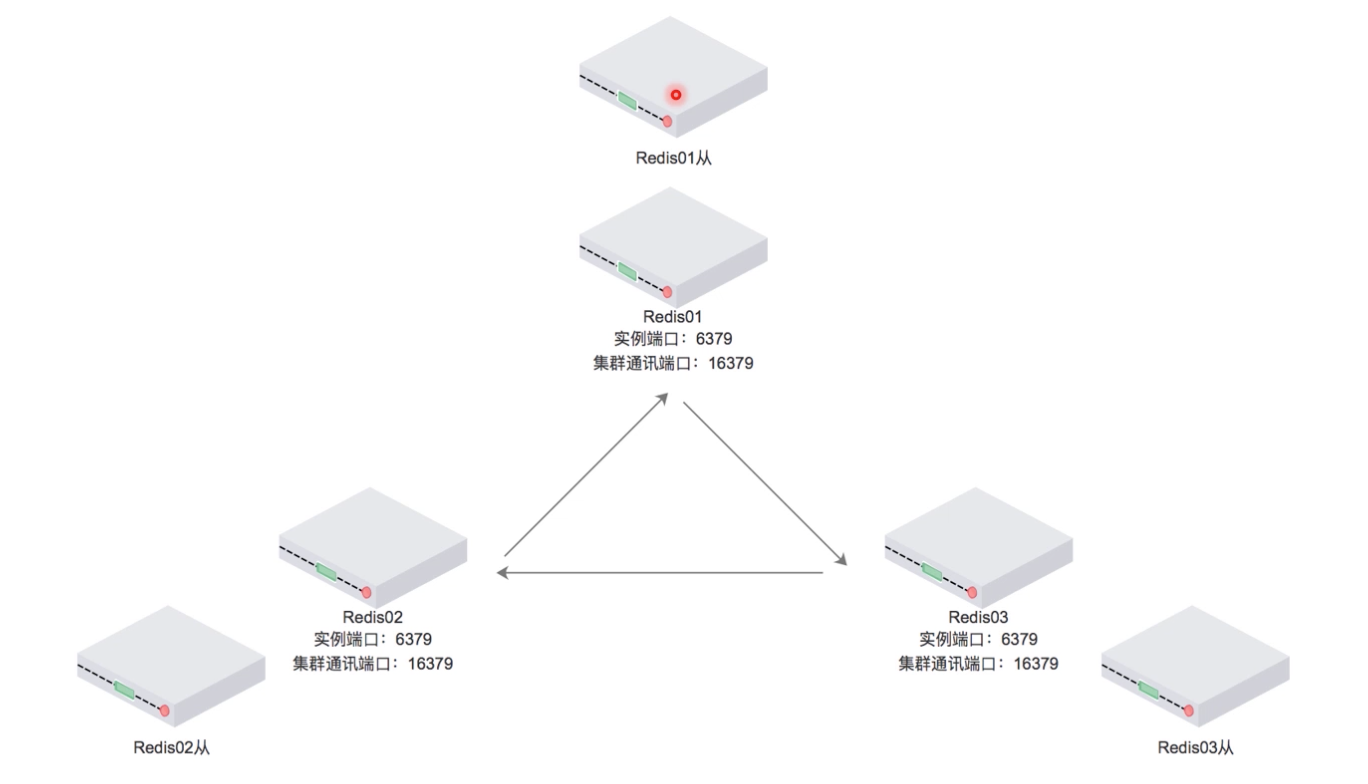
Redis主从同步
- Redis集群中的数据库复制是通过主从同步来实现的
- 主节点(Master)把数据分发给从节点(Slave)
- 主从同步的好处在于高可用,Redis节点有冗余设计
RedisCluster集群搭建
网络准备:
1 | docker network create --subnet=172.19.0.0/16 net2 |
镜像准备:
1 | docker pull grokzen/redis-cluster |
容器创建:
1 | docker run -it -d --name r1 -p 5001:6379 --net=net2 --ip 172.19.0.2 yyyyttttwwww/redis bash |
配置redis配置文件:(默认关闭了redis集群功能)
1 | //逐个进入容器,如: |
逐个启动redis服务
1 | /usr/redis/src/redis-server /usr/redis/redis.conf |
通过redis-trib.rb(redis自带,需要ruby环境)创建集群
1 | //进入任一容器,如: |
测试集群效果
1 | //逐个任一容器,如: |
Docker Compose
- Docker-Compose用于解决容器与容器之间如何管理编排的问题
- Dockerfile 可以让用户管理一个单独的应用容器;而 Compose 则允许用户在一个模板(YAML 格式)中定义一组相关联的应用容器(被称为一个 project,即项目),例如一个 Web 服务容器再加上后端的数据库服务容器等。
Compose 中有两个重要的概念
- 服务 (service) :一个应用的容器,实际上可以包括若干运行相同镜像的容器实例
- 项目 (project) :由一组关联的应用容器组成的一个完整业务单元,在 docker-compose.yml 文件中定义
Docker Compose 安装
Docker Compose 是 Docker 的独立产品,需自行安装
1 | sudo curl -L https://github.com/docker/compose/releases/download/1.21.2/docker-compose-$(uname -s)-$(uname -m) -o /usr/local/bin/docker-compose |
基本使用
- 启动服务:docker-compose up -d //在后台启动服务
- 查看启动的服务:docker-compose ps
- 停止服务: docker-compose stop
常用命令
1 | #查看帮助 |

